The Future of CAPTCHAs

When we click on a link for a website, we expect to be taken there. We rely on the reliability and speed of the entire system to provide that service. For a variety of nefarious – and often inexplicable – reasons some internet denizens use huge amounts of computer-generated traffic to overwhelm websites. These are known as denial-of-service (DoS) attacks. The perpetrators’ motives hardly matter. The damage potential is high, including the complete shut-down of websites and online services. Protecting against those huge traffic flows is just one of the reasons website operators choose to have Content Delivery Networks (CDNs) host their sites.
CDNs run a geographically distributed network of servers to deliver content to internet users. In addition to protection against DoS attacks, CDNs provide users with faster load times, greater overall reliability, and general security. They are particularly popular among streaming services, ecommerce platforms, and some SaaS providers.
One way CDNs and cloud networks protect the sites they host is to use CAPTCHAs to distinguish human users from DoS or other bot traffic. CAPTCHAs try to identify humans by measuring something a computer cannot do. Examples include detecting pictures of bicycles, solving an arithmetic problem, moving a jigsaw piece to complete a puzzle, or just clicking a button in a human way.
CDNs run a geographically distributed network of servers to deliver content to internet users. In addition to protection against DoS attacks, CDNs provide users with faster load times, greater overall reliability, and general security. They are particularly popular among streaming services, ecommerce platforms, and some SaaS providers.
One way CDNs and cloud networks protect the sites they host is to use CAPTCHAs to distinguish human users from DoS or other bot traffic. CAPTCHAs try to identify humans by measuring something a computer cannot do. Examples include detecting pictures of bicycles, solving an arithmetic problem, moving a jigsaw piece to complete a puzzle, or just clicking a button in a human way.
Example of a Cloudflare CAPTCHA protecting a South African tech news website
Another safeguard is rate limiting. It is a mechanism that limits the rate of service, or the frequency of requests by a user. It is put in place to restrict the number of requests from a client within a small timeframe, protecting the system from automated, very rapid bot requests associated with denial-of-service attacks.
Users dislike CAPTCHAs and rate limiting as they interrupt the journey to and use of a website. At best, they slow users down. At worst, they deny users access to a website because they have a disability that doesn’t let them solve the CAPTCHA.
But these are the tools CDNs have had available to them. Up until now. They’ve relied on these techniques because they don’t know much about the intended distribution of users across each network. Since the audience is unknown the dangerous among them can’t be identified in any useful way.
The Challenge of Classifying Users
The owners of a website want as much legitimate traffic as possible. The CDNs hosting the site wants to filter attack traffic as it adds cost to them without adding revenue. Users don’t want their legitimate traffic misclassified as harmful or dangerous because it means their experience is less good. But characterizing a user upon arrival at a website is more difficult than it might seem.
Many companies have hundreds of users behind a small NAT prefix. While some access networks have only one subscriber per IPv4 address or IPv6 prefix, others put many subscribers behind each unique IPv4 address. This maximizes the utility of a small number of IP addresses but disguises the number of users with access to them. These access providers rely on Carrier Grade NAT, also known as Large Scale NAT. It’s a technique where many subscriber NATs sit behind a NAT run by the ISP.
For hosts trying to control access, knowing what lies behind an individual IP address would allow characterizing the number and kind of users of it. So, if CDNs knew how other networks distribute users across the IP address space, they could use that information to challenge fewer people with a CAPTCHA. Website owners would be happy at turning away fewer legitimate users. They don’t want to expose the website to attack traffic but also don’t want the cost of serving the site in a way that generates attack traffic or adds cost. And users would be happy to get faster access to a website.
The good news is that internet engineers have developed a new information-sharing format to meet the CDNs’ needs. It uses the same method that’s proven successful for geolocation information. Each network operator (like ISPs) can choose to publish a small, structured data file and link to it from their entry in the RIR’s or NIR’s database.
By sharing information about how users are distributed across their network, they can let CDNs know how much traffic to expect from each IP address or IP prefix. A company NAT might deliver hundreds of users while a domestic residence should only provide a handful.
If it were universally adopted and maintained, this simple approach would mean that CDNs could make better-informed and more-nuanced decisions. And that means fewer CAPTCHAs and less rate limiting.
Of course, some users put their traffic through consumer VPNs and similar services, like iCloud Private Relay. These users probably won’t see these benefits. These services are designed to hide the originating IP address. They blend many users’ traffic behind a few IP addresses, undoing the benefit of the data sharing.
The Plan
The standard has not yet been published as an RFC, the final stage of development. But draft-ietf-opsawg-prefix-lengths, the document the format was agreed in, is ready for deployment. The RFC Editor will publish it soon.
The first step of deployment is to update the RIR and NIR databases with a new attribute – a line in the record – allowing the network operators to link to their data file. Then, the network operators can start publishing this data. Finally, the CDNs can start using the data, improving everyone’s experience.
The RIPE NCC is one of the five RIRs and the software it develops for the RIPE Database is also used by AFRINIC and APNIC. That means that one small change can deliver support in two-thirds of the RIRs. Fortunately, they have already committed to adding support.
The new attribute will be called “prefixlen:”. Networks will be able to use it to publish the HTTPS URL of their data file. This attribute will be returned by default when people query the database and will be available in bulk data downloads.
Network operators will publish a simple Comma Separated Values file. It only has three pieces of information about parts of a network:
- The prefix or prefixes
- The size of subnets within those prefixes
- The number of subscribers or users behind a subnet
There are only three columns, which means just two commas per line. For a very small network with just one IPv4 and one IPv6 prefix, only two lines might be needed. For larger networks with many allocations and a variety of customer and product types, there could be many lines.
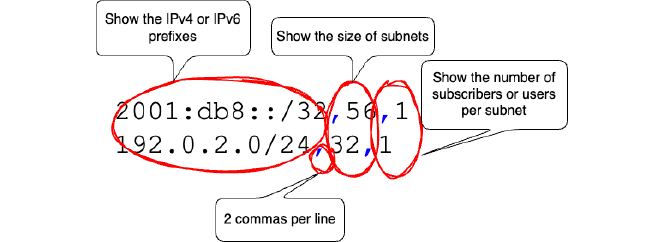
Two lines from an example Prefix Length file, with annotations
Small networks could probably handwrite the file and publish it anywhere that’s easy for them to change it. It doesn’t have to be on their corporate website. They could publish it on GitHub or a similar site that is highly available and free or inexpensive to use.
It is 2025 and security is a concern. So, while this format does not require a digital signature, it is supported. The digital signature would be tied back to the RPKI certificate for the network’s IP addresses.
Signed data is more trustworthy. But it requires extra steps from publishers and the CDNs who would process the data. So signing is optional. Nonetheless, it is likely to become increasingly important as the internet becomes more important and threats increase.
While the simple format means that this file could be compiled and published by a human, that leaves a door open to typing errors and delayed publication. This is exactly the sort of feature that could be automated by an IP Address Management system. We are likely to see them add support for Prefix Length files soon.