Today’s Infrastructure: Not Just Warehousing

Years ago, an organization’s infrastructure could run off a laptop without anyone noticing. Complexity and risk intruded on such simplicity. In addition, the crucial role of computing in business made technical operations not only important but vital. So, reliability and security became obvious business concerns for any growing organization. Plus, some businesses now face fines and regulatory action for downtime. So resilient data infrastructure is critically important.
That resilience can be implemented in multiple ways. Instead of just one machine running all aspects of the data warehouse service, a cluster might be used. And because administrators need to perform maintenance on clusters, multiple clusters might be required to ensure 24/7 availability. Those clusters must be managed and connected.
A whole service often must be replicated on different sites. This is important if an organization operates over large distances. It is also an important part of managing risk and making data infrastructure resilient.
An organization’s needs will dictate the data warehouse design selected. Fast internet access and distributed workforces mean that many organizations are deploying data warehouses in the cloud. But others choose to keep some or all of their data warehouse needs on-premise.
Not Just a Database
Data warehouses are more than just a database. They are a centralized set of systems used for reporting and analyzing data. They are key to business intelligence systems. They store current and historical data in ways that are optimized for analysis by managers.
Getting data from various sources into a data warehouse often involves a process known as Extract, Transform, and Load (ETL). Broadly speaking, it is used to get and clean data from a variety of sources, often in multiple formats, and include it in a database. For instance, medical data might be summarized by location, day or week, and age, among other factors.
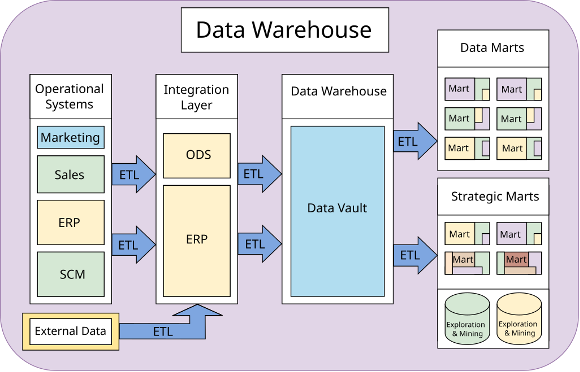
Data Warehouse and Data Mart overview by MarsJson published under CC BY-SA 4.0
That raw data is stored in what is often known as a data lake. This is the data that feeds into ETL and then ends up in data marts, where users access it. The raw data can be in almost any format: for instance, CSV, JSON, XML, or raw binary data.
There can be multiple data lakes feeding the ETL processes. For instance, a retail operation might analyze data supplied by financial partners, warehousing and logistics partners, and store-in-store retail partners, as well as owned retail locations.
The processed data is presented to consumers or other uses in data marts. They are generally focused on a specific area of analysis. Often, each department will own and manage its own data mart.
Resources, Clustering and Regions
Because they are so much more than just a simple database, they need more resources. Typically, they are deployed on clusters of machines – often virtual machines. Often, there will be an active cluster and a backup cluster.
Clusters can replicate elements of service to provide resilience if one fails or is removed from service for maintenance. And clusters need to be connected together and to each other, which means assigning IP addresses to the network infrastructure as well as the VMs. Oracle’s smallest cluster design requires 17 IPv4 addresses. That means using a /27 – a block of 32 IPv4 addresses. They also present designs for backup subnets. The largest design they can support uses a /16 – 65,536 IPv4 addresses.
Cloud providers offer their services in different regions. You can use two or more regions to add resilience to your data warehouse service. Resilient multi-region architectures are possible.
But not all the IP addresses need to be globally unique. Service addresses that provide access to data need to be globally unique. Often, these will be assigned to frontend systems like load balancers. The systems supporting the public frontend only need locally unique, private addresses.
Hybrid
You don’t have to go all-in for either cloud or for on-premises today. That includes data warehousing. Cloud can be cheaper while on-premises can give you more control and lower some risks.
A hybrid approach can be used to manage cost, availability, and risk in a way that aligns with your business needs. For instance, sensitive data can be kept on premises, or processed into less sensitive data. Cloud services can be used for other parts of your data warehouse.
Success depends on understanding what you need to get out of the data warehouse and the risks you must manage. A key part of that will be an understanding of the regulations that must be complied with, in particular any data sovereignty requirements that exist now and are being considered for the future.
Think Tank Europa worries that “the balance between competitiveness and sovereignty in tech could shift fast” because “Europe could make unprecedented moves to free itself from dependencies if they become choking.” Organizations with operations in the EU should consider this risk.
Knowing how to run on-premises services could be a useful skill to retain.